
Big data has opened doors never before
considered by many businesses. The idea of utilizing unstructured data for
analysis has in the past been far too expensive for most companies to consider.
Thanks to technologies such as Hadoop, unstructured data analysis is
becoming more common in the business world.
Business owners may be wondering if the current use of data warehousing could give them insights as versatile as big data. To understand the current scenario and future possibilities lets starts with understanding the difference between structured and
unstructured data.
Structured
Data
Data that resides in a fixed field within a
record or file is called structured data. This includes data contained in
relational databases and spreadsheets. Although data in XML files are not fixed
in location like traditional database records, they are nevertheless
structured, because the data are tagged and can be accurately identified. Structured
data first depends on creating a data model – a model of the types of business
data that will be recorded and how they will be stored, processed and accessed.
This includes defining what fields of data will be stored and how that data
will be stored: data type (numeric, currency, alphabetic, name, date, address) and
any restrictions on the data input. Structured data has the advantage of being
easily entered, stored, queried and analyzed.

Unstructured
Data
Unstructured data refers to
information that either does not have a pre-defined data model or
is not organized in a pre-defined manner. This results in irregularities
and ambiguities that
make it difficult to understand using traditional computer programs as compared
to data stored in fielded form in databases or annotated in
documents. Some examples of unstructured data are photos and graphic images,
videos, streaming instrument data, webpages, pdf files, PowerPoint
presentations, emails, blog entries, wikis and word processing documents.
Present
state of data
Today,
multinational companies and large organizations have operations in places that
are scattered around the world. Each place of operations may generate large
amount of both structured and unstructured type of data. They need very rapid
access to more insights and they cannot afford to wait—else they lose a
competitive edge. For IT organizations, this means delivery of relevant, timely
insights faster than ever before. Thus, data creation, storage, retrieval and
analysis varies in terms of volume, variety and velocity.
Volume:

Variety:

Velocity: Data is
streaming in at unprecedented speed and must be dealt with in a timely manner.
RFID tags, sensors and smart metering are driving the need to deal with
torrents of data in near-real time. Reacting quickly enough to deal with data
velocity is a challenge for most organizations.
Data
Warehouse

Data warehouse is defined as a subject-oriented, integrated, time-variant, and nonvolatile collection
of data in support of management's decision-making process. In this definition the data is:
• Subject-oriented as the
warehouse is organized around the major subjects of the enterprise (such as
customers, products, and sales) rather than major application areas (such as
customer invoicing, stock control, and product sales). Date warehouse is
designed to support decision making rather than application oriented data.
• Integrated because of the coming
together of source data from different enterprise-wide applications systems.
The source data is often inconsistent using, for example, different formats.
The integrated data source must be made consistent to present a unified view of
the data to the users.
• Time-variant because data in the
warehouse is only accurate and valid at some point in· time or over some time
interval.
• Non-volatile as the data is not
updated in real time but is refreshed from on a regular basis from different
data sources. New data is always added as a supplement to the database, rather
than a replacement. The database continually absorbs this new data,
incrementally integrating it with the previous data.
Interesting things to note from
the definition are:
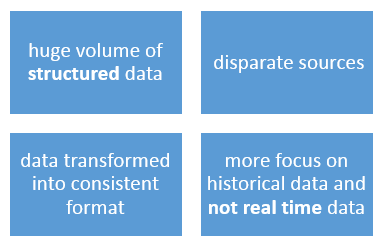
Limitations
of Data Warehouse from data perspective
While
data warehouse works perfectly with structured data, it is far from handling
unstructured data such as images, videos, emails, webpages, etc. Some of the
data comes in forms of Excel spreadsheets or PowerPoint presentations. There is
no easy way to get access to the data and it requires intensive manual
processing to gather the data and create reports. Also, with the excitement
about big data in the market, when organizations are leaving no stone unturned
to gain even a tiny portion of competitive edge, data warehousing is at a
disadvantage.
Furthermore,
data is hosted on various systems which make silos of information. Fulfilling
warehouse with data requires extracting, transforming and loading - processes which
are quite time consuming. Thus, a data warehouse is not suitable to process
real time instantaneous data.
Other Limitations
One of the problem with data warehouses is their cost. Like
all advanced technology, when data warehouses were first introduced, only the
truly wealthy companies could afford them. Even today, most data warehouses are
outside the price range of many companies. While vendors in recent years have
begun tailoring their products towards small to medium sized businesses, many
of these companies may not see the need of using a system that is overly complex.
Another problem is that in the past, it wasn’t uncommon for
a data warehouse project to take many months for implementation. Most firms
today want results, and they want them fast. They don’t see the need for
waiting months on a system and it will take time before a company begins seeing
a return on their investment. Many firms simply don’t have the patience to wait
for these returns.
Future of
Data warehouse
Automation

Data warehouses is facing strong competition from the rising
“data lake” architecture based on Hadoop. Data lakes provide cost savings on
software and storage. Newer organizations are adopting this strategy for economic
reasons. However, data lakes specifically and Hadoop in general has the
downside of “time to implementation”. Data warehouse will face huge
changes from the world of data warehouse automation. Just like we no longer hand
code ETL scripts, we can see productization of data modeling and database administration
to speed up time to implementation in the future, increase efficiency and optimize use of resources.
Data warehouse with real time dashboards

Today’s data warehouses are not moving at the speed of the
business. It takes forever to integrate a new data source into your data
warehouse. You have to figure out what reports you’re going to want so you can
pre-define data dimensions for aggregation. You have to figure out a schema
that can accommodate all the data you’re going to include. You have to set up
ETL to translate your operational data into that analytic schema, and you have
to maintain separate technology stacks at the operational, analytic, and
archive tiers. This kind of traditional data warehouse is resistant to change.
The trend is moving towards operationalizing the data from the data warehouse.
This means building data services that can combine data from multiple sources
and provide that data securely and performant to an operational process so that
process can complete in real time. Fraud detection, eligibility for benefits,
and customer onboarding are all examples of use cases that used to be performed
offline but now need to be performed online in real-time.
References
http://www.webopedia.com
http://www.pcmag.com/encyclopedia
http://en.wikipedia.org
http://ecomputernotes.com
http://www.exforsys.com/tutorials/data-warehousing
http://www.bisoftwareinsight.com
No comments:
Post a Comment